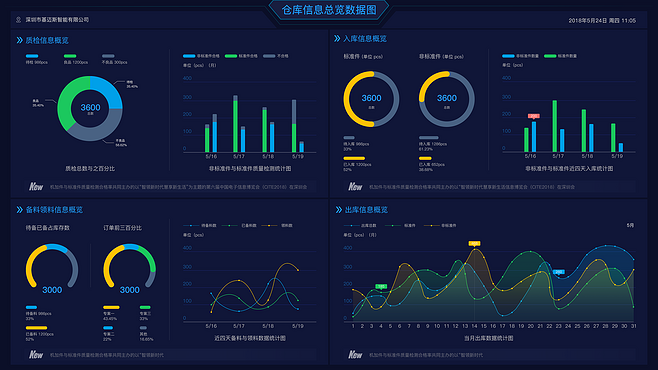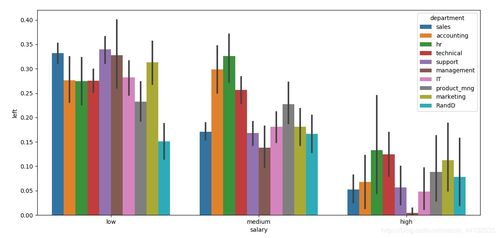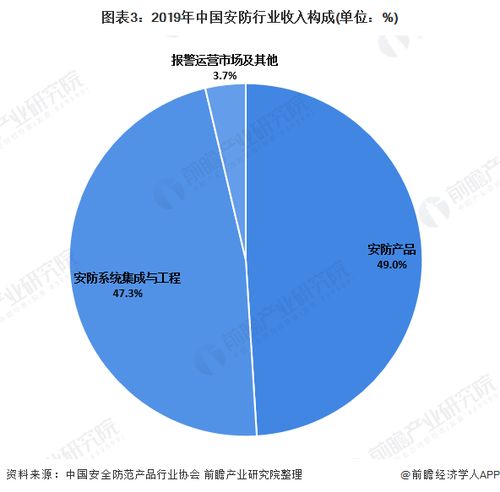
在当今数据驱动的决策环境中,数据分析不仅是处理数字的艺术,更是揭示现象背后规律的科学。而支撑这一科学过程的核心,是一系列经过时间检验的统计模型。这些模型为我们提供了从数据中提取信息、检验假设、预测未来的结构化方法。本文将系统性地介绍在数据分析领域中应用最为广泛、基础也最为关键的七大统计模型,并阐述其在数据统计与分析中的核心作用。
1. 线性回归模型
线性回归是探索变量间关系的基石。它通过拟合一条直线(或在多元情况下一个超平面)来描述一个或多个自变量(X)与一个连续型因变量(Y)之间的线性关系。其核心公式为 Y = β₀ + β₁X₁ + ... + βₖXₖ + ε。该模型不仅用于预测(如根据广告投入预测销售额),其回归系数β更能直观解释“X变化一个单位,Y平均变化多少”,是因果推断与趋势分析的起点。
2. 逻辑回归模型
当因变量是二分类(如是/否、成功/失败)时,线性回归不再适用。逻辑回归通过逻辑函数(Logistic Function)将线性组合的结果映射到[0,1]区间,用以估计某个事件发生的概率。它广泛用于信用评分、疾病诊断、客户流失预测等场景,是分类问题的入门利器与标杆模型。
3. 方差分析模型
方差分析(ANOVA)主要用于检验两个或以上组别的均值是否存在显著差异。其基本思想是将数据的总变异分解为组间变异和组内变异。通过比较这两种变异的比例(F检验),可以判断不同处理或分类是否对观测结果产生了显著影响。它在A/B测试、实验设计、心理学和社会学研究中是至关重要的工具。
4. 时间序列模型
时间序列模型专门处理按时间顺序排列的数据,其核心是考虑数据点之间的时间依赖性与趋势。经典模型如自回归模型(AR)、移动平均模型(MA)以及二者的结合(ARIMA)。这些模型旨在捕捉趋势性、季节性和周期性,广泛应用于经济预测、股票分析、销售预测和气象预报等领域。
5. 主成分分析与因子分析
这两种都属于降维模型,旨在用少数几个不相关的综合变量(主成分或因子)来代表原始数据中的大部分信息。主成分分析(PCA)侧重于最大化方差,是一种纯粹的数学变换;因子分析(FA)则试图发现背后潜在的、不可观测的“因子”来解释变量间的相关性。它们常用于数据可视化、简化数据结构、消除多重共线性及构建综合指标。
6. 聚类分析模型
聚类分析是一种“无监督学习”方法,目标是在没有预先标签的情况下,将数据集中的样本划分为若干个组(簇),使得同一簇内的样本彼此相似,而不同簇的样本相异。K-Means聚类和层次聚类是最常用的方法。它在客户细分、市场研究、图像分割和异常检测中发挥着关键作用,帮助我们发现数据中内在的群组结构。
7. 生存分析模型
生存分析专门处理“时间直到某个事件发生”的数据,例如设备故障时间、客户流失时间、患者生存时间。其独特之处在于能够妥善处理“删失数据”(即在研究结束时事件尚未发生的数据)。Cox比例风险模型是其核心,它可以评估多个风险因素对事件发生时间的影响。该模型在医学、工程可靠性、金融风险等领域不可或缺。
模型的选择与应用之道
这七大统计模型构成了数据分析方法论的支柱。在实际应用中,模型的选择绝非生搬硬套,而应始于对业务问题的清晰定义、对数据本质的理解(如数据类型、分布、关系)以及对模型假设的审慎检验。一个优秀的数据分析师,应善于将这些模型作为工具,结合领域知识,构建从数据到洞察、从洞察到决策的桥梁。理解并掌握这七大模型,便掌握了开启数据宝藏的七把钥匙,为深入更复杂的机器学习与人工智能领域奠定了坚实的统计基础。