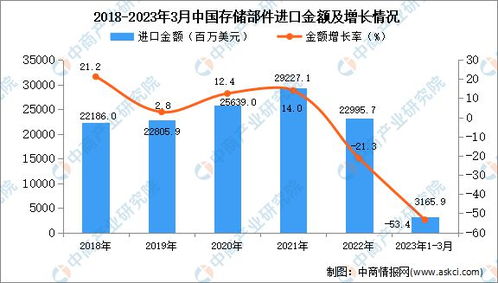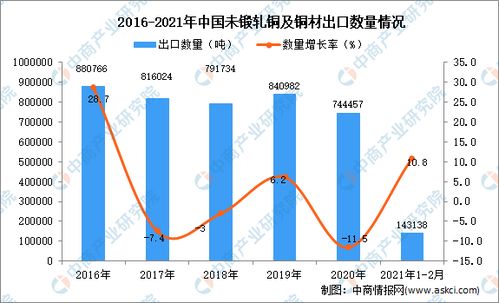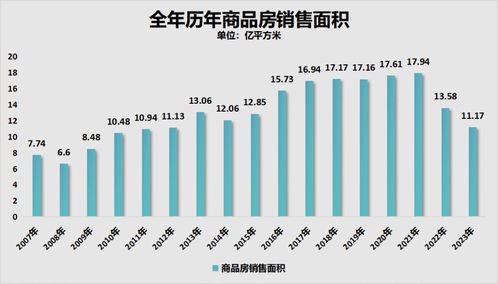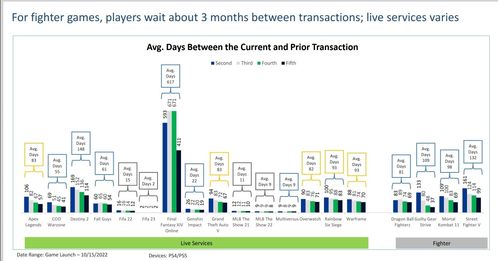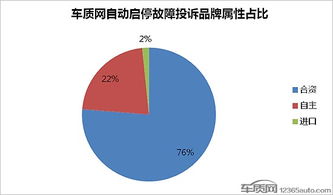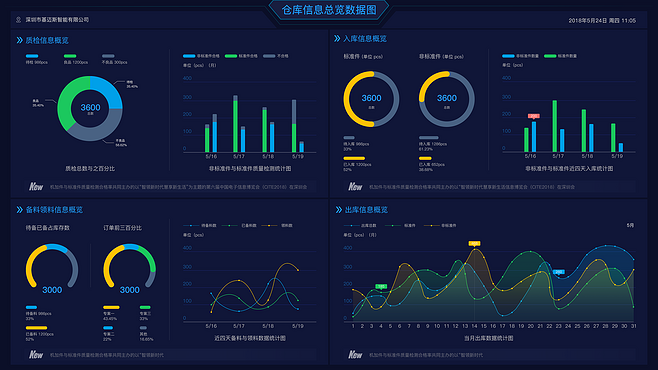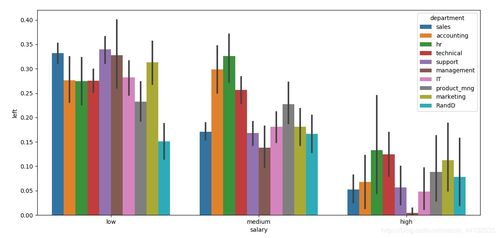
在数据科学和商业智能领域,探索性数据分析(EDA)是理解数据、揭示潜在模式、发现异常值并提出初步假设的关键第一步。当面对包含多个相互关联因子(变量)的复杂数据集时,传统的单变量分析往往力有不逮。此时,基于统计方法的多因子探索性数据分析便成为一项强大且必要的工具。它通过系统的统计技术,帮助我们理解多个因子之间的联合分布、相互关系和整体结构。
多因子EDA的核心目标
多因子EDA的核心目标不仅仅是描述单个变量的特性,更重要的是:
- 理解因子间的关系:探究两个或多个变量之间是否存在关联、是线性还是非线性关系、以及关联的强度和方向。
- 识别数据中的模式与结构:发现潜在的聚类、趋势、周期性或交互效应。
- 检测异常与不一致性:找出在多维空间中偏离主体模式的观测点(离群值)。
- 评估数据质量与分布:检查数据的完整性、一致性,并了解多个变量的联合分布形态。
- 为后续建模提供指导:为特征选择、模型构建(如回归、分类)和假设检验奠定基础。
关键统计方法与可视化技术
多因子EDA通常结合统计量计算和可视化手段,以下是一些核心方法:
1. 描述性统计汇总
- 中心趋势与离散度:计算每个因子的均值、中位数、标准差、四分位距等。对于多因子,可以生成汇总统计表。
- 相关分析:
- 皮尔逊相关系数:衡量连续变量间的线性相关程度。可以生成相关矩阵,并通过热图可视化,快速识别强相关的因子对。
- 斯皮尔曼秩相关系数:用于评估单调关系,对异常值不敏感。
- 卡方检验:用于检验两个分类变量之间的独立性。
2. 多变量可视化
- 散点图矩阵:将多个因子的两两散点图组织在一个矩阵中,是观察所有成对关系的经典工具,能直观揭示线性、非线性关系及聚类。
- 平行坐标图:适用于高维数据,每个观测值用一条跨越多条垂直轴的折线表示,有助于观察模式、聚类和异常值。
- 热图:除了显示相关矩阵,也可用于展示按某些因子聚合后的数值(如均值矩阵)。
- 气泡图:在二维散点图基础上,用点的大小表示第三个连续因子的值,用颜色表示第四个(分类或连续)因子。
- 成对图:结合了散点图、直方图(或密度图)和有时显示的相关性数值,是综合性极强的EDA工具。
3. 降维与结构探索
- 主成分分析:通过线性变换将原始相关变量转换为少数几个不相关的主成分,并可视化数据在前两个或三个主成分上的投影,以观察数据的总体结构和潜在聚类。
- t-SNE与UMAP:更先进的非线性降维技术,特别擅长在二维或三维空间中保留高维数据的局部结构,用于探索复杂的聚类模式。
4. 分组与聚合分析
- 分组统计:按一个或多个分类因子进行分组,计算其他连续因子的统计量(如组均值、中位数),并通过箱线图或小提琴图进行可视化比较,以发现组间差异和交互作用。
- 方差分析(ANOVA):检验一个连续因子的均值在不同组(由一个或多个分类因子定义)间是否存在显著差异,是多因子比较的统计基石。
5. 交互效应探索
- 通过条件散点图(将数据按某个分类因子分层后绘制散点图)或使用统计模型(如带交互项的线性模型)的系数来初步探索因子间的交互作用,即一个因子对结果的影响是否依赖于另一个因子的水平。
实施流程建议
- 数据准备与清洗:处理缺失值、异常值(在多维背景下谨慎定义),进行必要的变量转换(如对数化)。
- 单变量与双变量分析:先对每个因子及重要的因子对进行初步分析,建立基本认知。
- 多变量关系探索:应用上述散点图矩阵、相关分析、降维等方法,系统地审视所有因子。
- 深入挖掘与假设生成:针对发现的模式(如聚类、强相关、异常群组),进行更深入的子集分析或统计检验,并形成可用于后续验证的假设。
- 记录与迭代:完整记录分析步骤、发现和洞见。EDA是一个迭代过程,新的发现可能促使返回之前的步骤进行更深入的分析。
###
基于统计方法的多因子探索性数据分析是一个从整体到局部、从描述到洞察的迭代过程。它强调让数据“自己说话”,通过严谨的统计量和直观的可视化,将高维复杂的数据集转化为可理解的信息和可验证的假设。熟练掌握这一套方法,能够为任何数据驱动型项目奠定坚实可靠的基础,确保后续的建模与推断建立在对数据的深刻理解之上。